
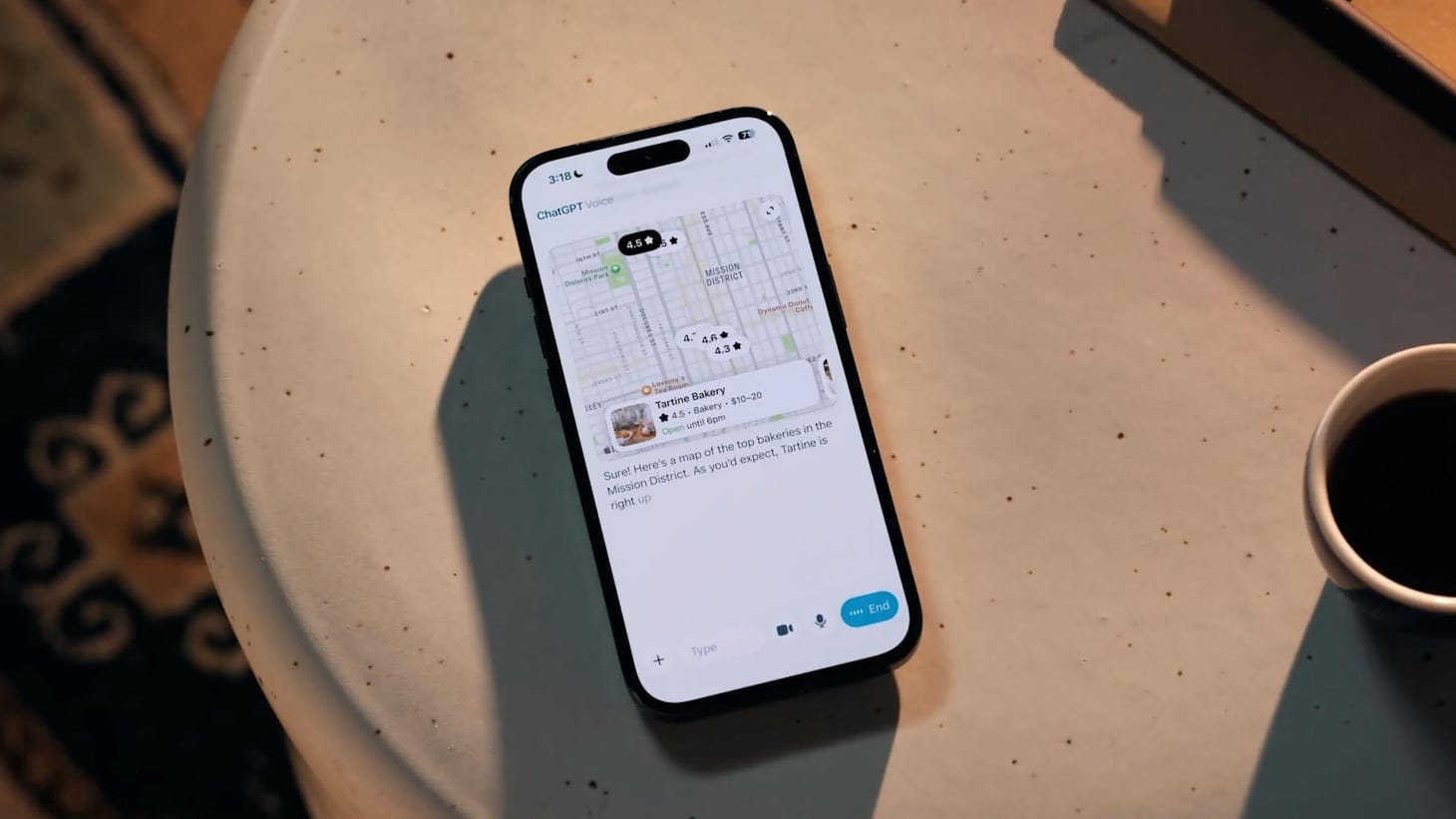

Представьте: вы обсуждаете проект голосом с ChatGPT. Прямо в этом же окне появляется карта. Или схема. Или график. Без переключений. Без прерываний. OpenAI интегрировала голосовой режим в основной интерфейс чата. Теперь текст, голос и визуальный контент работают в едином пространстве.
Что это такое
Мультимодальный голосовой режим — это работа с разными форматами сразу. Система понимает голос. Отвечает голосом. Создаёт картинки. Пишет текст. Всё в одном окне. Это не просто голосовой ассистент. Это инструмент, где разные способы общения работают одновременно. Не по очереди.
Почему это важно
Раньше голосовые ассистенты подходили для простых задач. Узнать погоду. Установить таймер. Для сложной работы приходилось переключаться на текст. Теперь граница стирается. Можно вести полноценный рабочий диалог голосом. Получать визуальные материалы. Сохранять текстовую документацию. Это экономит время. Снижает когнитивную нагрузку.
Что изменилось в голосовом режиме ChatGPT
Голосовой режим теперь встроен в обычный чат. Раньше требовалось открывать отдельный интерфейс. Это было полноэкранное окно: ассистент слушал и отвечал голосом, а визуальные материалы и стенограмма были ограничены.
Теперь достаточно нажать значок «волны» рядом с полем ввода. Голосовой режим активируется прямо в текущей беседе. Это означает три важных изменения.
Первое: вы переключаетесь между голосом и текстом в одном диалоге. Второе: система автоматически сохраняет транскрипт — текстовую расшифровку всего разговора. Третье: во время голосового разговора ChatGPT может генерировать визуальный контент. Карты, диаграммы, изображения появляются в том же окне.
Для тех, кто привык к прежнему формату, OpenAI оставила возможность вернуться к полноэкранному интерфейсу. В настройках голосового режима есть опция «Раздельный режим».
Как работает мультимодальное взаимодействие
Единое окно для разных типов информации
Представьте кухню. Раньше вы готовили на одной конфорке. Теперь работают все четыре. Плюс духовка. Плюс микроволновка. Одновременно. Так работает мультимодальный режим.
Вы спрашиваете голосом: «Покажи карту центра Казани с Кремлём». ChatGPT отвечает голосом. Объясняет расположение. Одновременно генерирует карту. Она появляется в окне чата. Вы видите визуальный результат. Слышите пояснение. Можете продолжить диалог текстом или голосом.
Транскрипт сохраняется автоматически. Это решает главную проблему голосовых интерфейсов. Раньше разговоры часто были эфемерными: после завершения к ним было сложно вернуться. Теперь вся беседа фиксируется в тексте. Это важно для работы. Для обучения. Для документирования идей.
Переключение между модальностями
Система позволяет свободно переходить от голоса к тексту. Вы говорите вопрос. Затем печатаете уточнение. ChatGPT помнит оба запроса. Контекст сохраняется. Независимо от способа ввода.
Это особенно полезно, когда руки заняты. Вы готовите презентацию. Перемещаетесь между документами. Параллельно задаёте вопросы голосом. Система генерирует нужные материалы. Вы сразу видите их на экране. Не прерываете рабочий процесс.
Генерация визуального контента в реальном времени
Во время голосового диалога ChatGPT создаёт изображения, схемы и карты. Это не поиск готовых картинок: система генерирует визуальный контент на основе вашего запроса и подстраивает его под контекст беседы.
Пример: вы обсуждаете архитектуру микросервисов. Просите показать схему взаимодействия компонентов. ChatGPT создаёт диаграмму и объясняет голосом каждый элемент. Или вы планируете маршрут по городу — система может сгенерировать карту с отмеченными точками и прокомментировать, как лучше добраться.
Визуальный контент появляется синхронно с голосовым объяснением. Это усиливает понимание: когда вы одновременно слышите объяснение и видите иллюстрацию, информация усваивается быстрее.
Реальные примеры использования
Ниже — условные примеры использования.
Пример 1: Подготовка урока за 15 минут
Учитель истории Анна Петрова из Санкт-Петербурга готовила урок о Куликовской битве. Описала голосом, что нужно. ChatGPT сгенерировал карту сражения, схему расстановки войск и таймлайн событий. Раньше на поиск материалов уходил час. Теперь — 15 минут.
Пример 2: Создание мудборда (референс-борда) в метро
Дизайнер Михаил Соколов из Москвы ехал в метро на встречу с клиентом. Описал голосом концепцию интерьера. ChatGPT создал мудборд с цветовой палитрой, примерами мебели и текстурами. Михаил показал результат клиенту прямо на встрече. Сэкономил два часа работы.
Пример 3: Презентация за 20 минут
Студент Тимур Ахметов из Казани готовил презентацию по квантовым вычислениям. Объяснил голосом основные концепции. ChatGPT сгенерировал диаграммы, схемы кубитов и графики сравнения производительности. Тимур получил готовую визуальную базу для слайдов. Раньше на это уходил вечер. Теперь — 20 минут.
Комментарий редакции
Мультимодальные системы меняют пользовательский опыт: синхронная работа голоса, текста и изображения снижает когнитивную нагрузку и ускоряет понимание. Это особенно полезно в обучении и профессиональных задачах.
Распространённые заблуждения
Миф: Голосовой режим работает только на английском.
Реальность: Модели распознавания речи OpenAI (например, Whisper) поддерживают русский язык. Точность приемлема для чёткой речи в тихой обстановке, но снижается при шуме или сильном акценте. Английский по-прежнему даёт лучшую точность.
Миф: Транскрипт сохраняется на серверах OpenAI навсегда.
Реальность: Транскрипт хранится в вашей истории чата. Вы можете удалить его в любой момент. Использование данных для улучшения моделей можно отключить в настройках конфиденциальности.
Миф: Для работы нужен быстрый интернет.
Реальность: Нужна стабильная связь, но не обязательно сверхбыстрая. Достаточно обычного 4G. Генерация изображений при медленном соединении может занимать немного больше времени.
Технические аспекты и ограничения
Мультимодальные системы требуют значительных вычислительных ресурсов: обработка голоса в реальном времени, генерация изображений и поддержание контекста происходят одновременно. Это влияет на скорость отклика.
Доступность и объём функций зависят от тарифного плана и региона. Часть возможностей может быть доступна только на платных подписках (например, ChatGPT Plus, Team, Enterprise).
Качество распознавания русской речи зависит от акцента, скорости и фоновых шумов. Точность выше при чёткой, нейтральной речи в тихой обстановке и ниже — при шуме, сильном акценте или одновременной речи нескольких людей.
OpenAI применяет географические ограничения доступа. Доступность сервиса и отдельных функций может различаться по регионам.
Что это значит для будущего
Интеграция модальностей станет стандартом. Google развивает Gemini Live, Яндекс — собственные голосовые ассистенты. Будущее AI‑интерфейсов — в гибкости: пользователь выбирает, как взаимодействовать, а система подстраивается под его предпочтения.









